
By Alexander Kell, Dan Yamins, Erica Shook, Sam V. Norman-Haignere, Josh H. McDermott
Summary by Josue Ortega-Caro
In this work, the authors study the capabilities of a deep neural network to predict both neural responses of human auditory cortex and the behavior of human participants. In addition, the authors point to their results as evidence of hierarchical processing in the auditory cortex. Their results are part of a growing body of work that uses deep neural networks as models of human cortex (see [1] for references), especially the visual cortex.
The assumption behind this literature states that everyday perceptual tasks may impose strong constraints on the brain. These constraints may yield general principles of how tasks can be solved within a distributed network architecture. Therefore, deep neural networks trained directly on these perceptual tasks are likely to implement the same solutions as the cortex, and thereby exhibit brain-like representations and transformations.
Through comparisons to humans in several different noise conditions, the authors show the strong similarities between their models and humans in speech and music recognition tasks. These results suggest that deep neural networks also provide a good model for auditory cortex.
The authors used two tasks: speech and music recognition tasks. Every signal was preprocessed by transforming into a cochleogram prior to passing through the network. On the first task, subjects were given a two second clip of speech, and were asked to recognize one of 587 possible words in the middle of a sentence. On the second task, subjects listened to a two second clip of a song, and were asked to identify one of 41 possible genres to which it belongs. In addition, every two second clip was perturbed by different types and levels of background noise, as a way to compare the models’ and humans’ abilities to perform auditory recognition under difficult conditions.
First, the authors performed an architecture search over 180 architectures to find neural networks that perform well on speech and music recognition independently. Next they searched for ways to combine the architectures into a single network that performed both tasks. The authors argue that both speech and music recognition should share low-level auditory features similar to visual recognition tasks. (It was not clear why they wanted to combine networks trained on each task, except perhaps as a way of decreasing the number of parameters needed for both tasks together.) The final network has three parts: a shared-core (up to Conv3) for both tasks, followed by a word-classifier and a genre-classifier branches, selected by the performance on both the speech and music recognition tasks.
The authors compare the behavior (performance) of the model and humans under different noise conditions. Figure 2 shows that under five types of noise at six intensity levels, the human and model behavior have 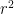
Moreover, they tested the ability of the model trained on speech and music recognition to predict fMRI recordings of 8 participants to 165 natural sounds. Some of these sounds were speech and music related but most (113 out of 165) were not. They did independent linear readouts from the activations of different layers of their network in order to find which layers better predict each voxel response to the 165 natural sounds. Figure 3 shows that median variance explained by their model is higher than a spatiotemporal model (baseline model) and a random network baseline. This shows that training the model did help its predictive power.
The most interesting results comes when they examine the fine-grain predictions of different model layers for different voxels in the auditory hierarchy. In Figure 4, their hierarchical map shows higher correlation between early layers of auditory cortex and the predicted voxels from the shared-core layers. At the same time, higher cortical areas have higher correlation with their respective task specific branch. In addition, they show that even though the shared layers can predict the higher cortical areas, the specific branches predict significantly better those areas compare to the shared-core and vice versa. Furthermore, music and speech specific voxels are better predicted by their respective branches of the model. Even though this result is very clear, we were not completely sure if the correlation differences are significant between speech and music branches.
Moreover, the authors explore the ability of their model to explicitly represent acoustic features of the stimulus (via linear decodability). They argue that this is a way to understand the representation learned by the model. They show the variance explained of the spectral filters is higher in early layers, and that variance explained of the spectral modulation peaks at intermediate layers. In contrast, the untrained network has a similar profile but not the same increase or decrease in decodability as the trained network. One experiment they might have done is linearly decode of the spectral filters on the fMRI data and see if the voxels that have higher decodability also have high correlation with the early layers of the network.
Lastly, the authors show in Figure 7 that networks at intermediate points during training explain variance that is correlated to its performance in the speech and music tasks. I think this is the clearest result of their philosophical position: There is a linear relationship between the network’s performance on an everyday task, and the presence of brain-like representational transformations.
In conclusion, the authors show a correlation between humans and deep neural networks in neural, behavioral and representational axis during speech and music recognition tasks. As stated before, this framework of task-optimized neural networks is becoming widespread throughout the neuroscience community, going from visual cortex [1], motor cortex [2], etc., and now to auditory cortex. It is important to note, as also noted by the authors, that the behavioral, neural and representational comparison done by the authors are only sufficient to suggest correlations between humans and deep neural networks. We still need more causal ways to compare both systems in order to see if the similarities are superficial (merely because of the highly-optimized nature of both humans and models on speech and music tasks) or if they reveal a deeper relationship between deep neural models and humans. In addition, we wondered if including other neural motifs such as recurrence, feedback modulation and cell-specific functions would help improve the results presented in this paper.
[1] Yamins, D. L., Hong, H., Cadieu, C. F., Solomon, E. A., Seibert, D., & DiCarlo, J. J. (2014). Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Sciences, 111(23), 8619-8624.
[2] Michaels, J. A., Dann, B., Intveld, R. W., & Scherberger, H. (2018). Neural dynamics of variable grasp movement preparation in the macaque fronto-parietal network. Journal of Neuroscience, 2557-17.