
Post by Aadith Vittala.
This paper serves as a review of similarity-based online unsupervised learning algorithms. These types of algorithms are important because they are biologically-plausible, produce non-trivial results, and sometimes work as well as other non-biological algorithms. In this paper, biologically-plausible algorithms have three main features: they are local (each neuron uses only pre or post synaptic information), they are online (data vectors are presented one at a time and learning occurs after each data vector is passed in), and they are unsupervised (there is no teaching signal to tell the neurons information about error). The simplest example of one of these algorithms is the Oja online PCA algorithm. Here, the system receives 


This algorithm is both biologically-plausible and potentially useful. This paper aims to find more algorithms like the Oja online PCA algorithm.
As a starting point, they aimed to develop a biologically-plausible algorithm that would output multiple principal components from a given data set. To do this, they chose to use a similarity-matching objective function, where the goal is to minimize the following expression

This expression essentially tries to match the pairwise similarities between input vectors to the pairwise similarities between output vectors. In previous work, they have shown that the solution to this problem (with 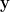
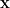
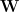
![\min_{\textbf{W}} \max_{\textbf{M}} \frac{1}{T} \sum_{t=1}^T \big[ 2 {\rm Tr\,}(\textbf{W}^T \textbf{W}) - {\rm Tr\,}(\textbf{M}^T \textbf{M}) +\min_{\textbf{y}_t} (-4 \textbf{x}_t^T \textbf{W}^T \textbf{y}_t + 2 \textbf{y}_t^T\textbf{M}\textbf{y}_t) \big]](https://s0.wp.com/latex.php?latex=%5Cmin_%7B%5Ctextbf%7BW%7D%7D+%5Cmax_%7B%5Ctextbf%7BM%7D%7D+%5Cfrac%7B1%7D%7BT%7D+%5Csum_%7Bt%3D1%7D%5ET+%5Cbig%5B+2+%7B%5Crm+Tr%5C%2C%7D%28%5Ctextbf%7BW%7D%5ET+%5Ctextbf%7BW%7D%29+-+%7B%5Crm+Tr%5C%2C%7D%28%5Ctextbf%7BM%7D%5ET+%5Ctextbf%7BM%7D%29+%2B%5Cmin_%7B%5Ctextbf%7By%7D_t%7D+%28-4+%5Ctextbf%7Bx%7D_t%5ET+%5Ctextbf%7BW%7D%5ET+%5Ctextbf%7By%7D_t+%2B+2+%5Ctextbf%7By%7D_t%5ET%5Ctextbf%7BM%7D%5Ctextbf%7By%7D_t%29+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
This expression leads to an online algorithm where you solve for 


and then update 


though after discussion, we think it would be better to call the second weights update “Hebbian for inhibitory synapses”. This online algorithm has not yet been proven to converge, but it gives relatively good results when tested. In addition, it provides a simple interpretation of
The paper goes on to generalize this algorithm to accept whitening constraints (via Lagrange multipliers), to work for non-negative outputs, and to work for clustering and manifold tiling. The details for all of these processes are covered in cited papers, but not in this specific paper. Overall, the similarity-matching objective seems to give well-performing biologically-plausible algorithms for a wide range of problems. However, there are a few important caveats: none of these online algorithms have been proved to converge for the correct solution, inputs were not allowed to correlate, and there is no theoretical basis for stacking (since multiple layers would be equivalent to a single layer). In addition, during discussion we noted that similarity matching seems to essentially promote networks that just rotate their input into their output (as similarity measures the geometric dot product between vectors), so it is not obvious how this technique can conduct the more non-linear transformations necessary for complex computation. Nonetheless, this paper and similarity-matching in general provides important insight into how networks can perform computations while still remaining within the confines of biological plausibility.