
by Yubei Chen, Dylan Paiton, and Bruno Olshausen
https://arxiv.org/abs/1806.08887
Theories of neural computation have included several different ideas: efficient coding, sparse coding, nonlinear transformations, extracting invariances and equivariances, hierarchical probabilistic inference using priors over natural sensory inputs. This paper combined a few of these in a theoretically satisfying way. It is not a machine-learning paper with benchmarks, but is rather a conceptual framework for thinking about neural coding and geometry. It can be applied hierarchically to generate a deep learning method, and the authors are interested in applying this to more complex problems and data sets, but haven’t yet.
The three main ideas synthesized in this paper are: sparse coding, manifold flattening, and continuous representations.
Sparse coding represents an input 

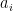


A manifold is a smooth curved space that is locally isomorphic to a Euclidean space. Natural images are often thought of occupying low-dimensional manifolds embedded within the much larger space of all possible images. That is, any single natural image with 

People have published several ways to flatten manifolds. One prominent one is Locally Linear Embedding [Roweis and Saul 2000], which expresses points on the manifold as linear combinations of nearby data points. A coarser and more compressed variant is Locally Linear Landmarks (LLL) [Vladymyrov M, Carreira-Perpinán 2013] which just uses a smaller set of points as “landmarks” rather than using all data. In both variants, each landmark 
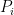


The SMT authors observe that sparse coding and manifold flattening are connected. Since you only use a few landmarks to reconstruct the original signal, the coefficients
Continuous representations: In general, sparse coding does not impose any particular organization on the dictionary elements. One can pre-specify some locality structure to the dictionary, as in Topographic ICA [Hyvärinen et al 2001] which favors dictionary elements 








The authors relate this idea to Slow Feature Analysis (SFA) [Wiskott and Sejnowski 2002], another unsupervised learning concept that I really like. In SFA, one finds nonlinear transformations 


There’s actually an interesting distinction to be drawn here: their manifold flattening should not throw away information, as do many models for extracting invariances, including SFA. Instead the coordinates on the manifold actually try to represent all relevant directions, and the flat representation ensures that changes in the appearance
Applications
Finally, the authors note that they can apply this method hierarchically, too, to progressively flatten the manifold more and more. Each step expands the representation nonlinearly to obtain a sparse code
They demonstrate their approach on one toy problem for illustration, and then apply it to time sequences of image patches. As in many other methods, they recover Gabor-like features once again, but they discover some locality to their Gabors and smoothness in the sparse coefficients and target representation. When applied iteratively, the Gabors seem to get a bit longer and may find some striped textures, but nothing impressive yet. Again I think the conceptual framework is the real value here. The authors plan on deploying their method on larger scales, and it will be interesting to see what emerges.
Discussion
Besides the foundational concepts (sparse coding, LLL, SFA), the authors only briefly mention other related works. It would be helpful to see this section significantly expanded, both in terms of how the conceptual framework relates to other approaches, and how performance compares.
One fundamental and interesting concept that the authors could elaborate substantially more is how they think of the data manifold. They state that “natural images are not well described as a single point on a continuous manifold of fixed dimensionality,” but that is how I described the manifold above: an image was just a point 

Yubei suggested this view could have a major benefit to hierarchical inference: “Just like we reuse the pixels for different objects, we can reuse the dictionary elements too. Sparsity models the discreteness of the signal, and manifolds model the continuity of the signal, so we propose that a natural way to combine them is to imagine a sparse function defined on a low dimensional manifold.”
The geometry of the sensory space is quite interesting and important and merits deeper thinking. It would also be interesting to consider how the manifold structure of sensory inputs affects the manifold structure of beliefs (e.g. posterior probabilities) about those inputs. This seems like a job for Information Geometry [Amari and Nagaoka 2007].
References:
Amari SI, Nagaoka H. Methods of information geometry. American Mathematical Soc.; 2007.
Hyvärinen A, Hoyer PO, Inki M. Topographic independent component analysis. Neural computation. 2001 Jul 1;13(7):1527-58.
Roweis ST, Saul LK. Nonlinear dimensionality reduction by locally linear embedding. science. 2000 Dec 22;290(5500):2323-6.
Rozell CJ, Johnson DH, Baraniuk RG, Olshausen BA. Sparse coding via thresholding and local competition in neural circuits. Neural computation. 2008 Oct;20(10):2526-63.
Vladymyrov M, Carreira-Perpinán MA. Locally linear landmarks for large-scale manifold learning. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases 2013 Sep 23 (pp. 256-271). Springer, Berlin, Heidelberg.
Wiskott L, Sejnowski TJ. Slow feature analysis: Unsupervised learning of invariances. Neural computation. 2002 Apr 1;14(4):715-70.