Uncovering the structure of cortical networks is a fundamental goal of neuroscience. Understanding how neuronal circuits are organized could help us understand, for instance, whether certain cell types connect preferentially to others. The patterns of connections could help explain the observed patterns of activity [1]. However, probing the patterns of synaptic connectivities directly using electrophysiological methods is difficult and expensive [2,3]. With the advent of new experimental techniques we can now record the concurrent activity of hundreds and even thousands of neurons in the cortex. It would be much simpler if we could infer the structure of cortical circuits directly from such recordings.
Inferring connectivity from activity is not a new idea: Cross-correlation functions measure the average impact of one cells’ spike on the activity of another directly from their concurrently measured spike trains. The idea that cross-correlations can be used to infer synaptic interactions between cells goes back to at least 1970 [4]. However, this early work also recognized several difficulties of this approach. Cross-correlations will reflect common inputs to the cells, and global patterns of activity of the observed populations. Disentangling synaptic interactions from these other effects is difficult, especially if only a fraction of a population is observed.
Assuming that the activity of an entire population  has been observed, one approach to disentangling direct from indirect interactions between cells is to use partial correlations: the correlations between the residuals of two cells’ activities remaining after regression on the other cells’ activities,
has been observed, one approach to disentangling direct from indirect interactions between cells is to use partial correlations: the correlations between the residuals of two cells’ activities remaining after regression on the other cells’ activities,  . In other words, partial correlations are the correlations that remain between two neurons when their correlations with all other cells are removed. Again, this is an old idea [5], and other approaches have been proposed to tackle the problem: the connectivity inferred by fitting Ising models, generalized linear models, and other types of models have been proposed to uncover synaptic interactions.
. In other words, partial correlations are the correlations that remain between two neurons when their correlations with all other cells are removed. Again, this is an old idea [5], and other approaches have been proposed to tackle the problem: the connectivity inferred by fitting Ising models, generalized linear models, and other types of models have been proposed to uncover synaptic interactions.
In our recent journal club we discussed a recent addition by Kadirvelu, et al [6] to this fairly extensive body of literature. Here the authors asked how well thresholded partial correlations and thresholded weights obtained from fitting an Ising model can represent synaptic connectivity. The authors first simulated networks of 11 to 120 Izhikevich neurons under varying conditions, changing the firing rates, connectivity structure, etc., of the network. They then tried to recover the connectivity using the two methods, and compare the results to the actual ground truth used in the simulations. Synaptic weights were deemed unimportant, and instead binary matrices with 0s and 1s signifying the absence or presence of an interaction, respectively, were compared. As partial correlations do not reveal the direction of an interaction, the ground truth matrices were symmetrized before a comparison. The performance of each method was quantified by the area under the ROC curve obtained from varying the threshold. Low thresholds gives more false positives, and high thresholds more false negatives. Thus as the threshold is changed from low to high, both the fraction of falsely identified synaptic connections (false positives, FP), and the fraction of correctly identified connections (true positives, TP) both increase. The curve traced out by the false and true positive rate in FP-TP space is the ROC curve.
The main conclusion of the paper is that the performance of the methods depends on the level of correlations: At low correlations, fitting an Ising model works better, and at high correlations the partial correlation method works better. Other observations were not unexpected: increasing the firing rates improves inference (as the number of “interactions”, i.e. spikes increases). As the number of neurons increases, inference was harder, etc.
One has to ask what testing these models using simulations can tell us: These settings are highly idealized, and miss many of the features one would encounter with real data. One of the main issues is that latent inputs are not accounted for. In this particular case, all correlations were due to synaptic interactions between model cells, and all cells were observed. Global fluctuations can also induce strong correlations [7], completely overshadowing the effects of direct interactions [1]. There are many other subtleties: the direct inversion of the correlation matrix to obtain partial correlations is problematic, and typically some regularization is required [8]. Moreover, thresholding of inferred interaction weights to try to distinguish real interactions from fluctuations is known to give inconsistent estimators of interactions.
So is the inference of interactions a futile exercise? With the present data, inferring synaptic interactions is likely to be unsuccessful in all but the simplest settings. However, robustly inferring the strength of interactions is still worthwhile, even if these only measure statistical dependencies, rather than structural connections. Changes in such effective connectivity may reflect computations or mental states, and are hypothesized to change under working memory load [9]. Moreover, the effective connectivity could be modulated much more quickly than synaptic connectivity. However, as to which method is best at robustly uncovering such effective connectivity, the article we discussed is silent.
1. Rosenbaum, R., Smith, M. A., Kohn, A., Rubin, J. E., & Doiron, B. (2016). The spatial structure of correlated neuronal variability. Nature Neuroscience, 20(1), 107–114.
2. Jiang, X., Shen, S., Cadwell, C. R., Berens, P., Sinz, F., Ecker, A. S., et al. (2015). Principles of connectivity among morphologically defined cell types in adult neocortex. Science 350(6264).
3. Oswald, A.-M. M., & Reyes, A. D. (2008). Maturation of intrinsic and synaptic properties of layer 2/3 pyramidal neurons in mouse auditory cortex. Journal of Neurophysiology, 99(6), 2998–3008.
4. Moore, G. P., Segundo, J. P., Perkel, D. H., & Levitan, H. (1970). Statistical signs of synaptic interaction in neurons. Biophysical Journal, 10(9), 876–900.
5. Brillinger, D. R., Bryant, H. L., & Segundo, J. P. (1976). Identification of synaptic interactions. Biological Cybernetics, 22(4), 213–228.
6. Kadirvelu, B., Hayashi, Y., & Nasuto, S. J. (2017). Inferring structural connectivity using Ising couplings in models of neuronal networks. Scientific Reports, 7(1), 8156.
7. Ecker, A. S., Denfield, G. H., Bethge, M., & Tolias, A. S. (2015). On the structure of population activity under fluctuations in attentional state.
8. Yatsenko, D., Josić, K., Ecker, A. S., Froudarakis, E., Cotton, R. J., & Tolias, A. S. (2015). Improved estimation and interpretation of correlations in neural circuits. PLoS Computational Biology, 11(3), e1004083.
9. Pinotsis, D. A., Buschman, T. J., & Miller, E. K. (n.d.). Working Memory Load Modulates Neuronal Coupling.


 neurons to identify a
neurons to identify a 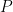 -dimensional subspace (
-dimensional subspace ( ) capturing a sufficient fraction of neural activity, and (ii) examine how neural dynamics evolve within this subspace to (hopefully) gain insights about neural computation. This recipe has largely been successful
) capturing a sufficient fraction of neural activity, and (ii) examine how neural dynamics evolve within this subspace to (hopefully) gain insights about neural computation. This recipe has largely been successful 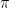 , the activity of the neural population will likely change too. If
, the activity of the neural population will likely change too. If  denotes the minimum change in orientation required to induce an appreciable change in the population activity (i.e. the width of the autocorrelation in the population activity pattern), then the population will be able to explore roughly
denotes the minimum change in orientation required to induce an appreciable change in the population activity (i.e. the width of the autocorrelation in the population activity pattern), then the population will be able to explore roughly  linear dimensions. Of course, the scale of autocorrelation will differ across brain areas (presumably increases as one goes from the retina to higher visual areas), so the neural dimensionality would depend on the properties of the population being sampled, not just on the task design. Similar reasoning applies to other task parameters such as time (yes, they consider time as a task parameter because, after all, neural activity is variable in time). If you wait for time period
linear dimensions. Of course, the scale of autocorrelation will differ across brain areas (presumably increases as one goes from the retina to higher visual areas), so the neural dimensionality would depend on the properties of the population being sampled, not just on the task design. Similar reasoning applies to other task parameters such as time (yes, they consider time as a task parameter because, after all, neural activity is variable in time). If you wait for time period  , the dimensionality will be roughly equal to
, the dimensionality will be roughly equal to  where
where  is now the width of temporal autocorrelation. For the general case of
is now the width of temporal autocorrelation. For the general case of  different task parameters, they prove that neural dimensionality
different task parameters, they prove that neural dimensionality  is ultimately bounded by (even if you record from millions of neurons):
is ultimately bounded by (even if you record from millions of neurons):
 is the range of the
is the range of the  task parameter,
task parameter,  is the corresponding autocorrelation length and
is the corresponding autocorrelation length and  is an
is an 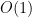 constant which they prove is close to 1. The numerator and denominator depend on task design and smoothness of neural dynamics respectively, so they label the term on the right-hand side neural task complexity (NTC). This terminology was a source of confusion among some of us as it appears to downplay the fundamental role of the neural circuit properties in restricting the dimensionality, but its intended meaning is pretty clear if you read the paper.
constant which they prove is close to 1. The numerator and denominator depend on task design and smoothness of neural dynamics respectively, so they label the term on the right-hand side neural task complexity (NTC). This terminology was a source of confusion among some of us as it appears to downplay the fundamental role of the neural circuit properties in restricting the dimensionality, but its intended meaning is pretty clear if you read the paper. where
where 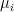 are the eigenvalues of the neuronal covariance matrix, instead of the more common but analytically cumbersome measure based on ‘fraction
are the eigenvalues of the neuronal covariance matrix, instead of the more common but analytically cumbersome measure based on ‘fraction  of variance explained’
of variance explained’  , but they demonstrate that their choice is reasonable.
, but they demonstrate that their choice is reasonable. large denominator) to specific tasks (low complexity
large denominator) to specific tasks (low complexity 


 . After all,
. After all,  . To explore this, the authors use the theory of random projection and show that it is possible to achieve some desired level of fractional error
. To explore this, the authors use the theory of random projection and show that it is possible to achieve some desired level of fractional error  in estimating the neural trajectory by ensuring:
in estimating the neural trajectory by ensuring:![\displaystyle M(\epsilon)=K[O(log\ NTC)\ +\ O(log\ N)\ +\ O(1)]\ \epsilon^{-2} \qquad \qquad (2)](https://i0.wp.com/xaqlab.com/wp-content/ql-cache/quicklatex.com-4ef6f12a6177e3530e4a7a414e747f6a_l3.png?resize=491%2C21&ssl=1 "Rendered by QuickLaTeX.com")

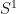






 ),
), 







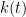




 is close to
is close to 



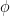


 , and model parameters
, and model parameters  , they use the following ingredients for their theory: a prior
, they use the following ingredients for their theory: a prior 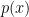 , a likelihood
, a likelihood  , an encoding capacity constraint
, an encoding capacity constraint  , and a loss functional
, and a loss functional  . They assume that the brain is able to construct the true posterior
. They assume that the brain is able to construct the true posterior  . The goal is to find a model that optimizes the expected loss
. The goal is to find a model that optimizes the expected loss![\bar{L}(\theta)=\mathbb{E}_{p(y|\theta)}\left[L(p(x|y,\theta))\right]](https://s0.wp.com/latex.php?latex=%5Cbar%7BL%7D%28%5Ctheta%29%3D%5Cmathbb%7BE%7D_%7Bp%28y%7C%5Ctheta%29%7D%5Cleft%5BL%28p%28x%7Cy%2C%5Ctheta%29%29%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
 .
. , or the ground truth
, or the ground truth  . They needed to make the loss explicitly dependent on the posterior in order to optimize for mutual information. It was unclear whether they also considered a loss depending on both, which seems critical. We communicated with them and they said they’d clarify this in the next version.
. They needed to make the loss explicitly dependent on the posterior in order to optimize for mutual information. It was unclear whether they also considered a loss depending on both, which seems critical. We communicated with them and they said they’d clarify this in the next version.![L(x,p(x|y))=\mathbb{E}_{p(x|y)}\left[\left|x-\hat{x}(y)\right|^p\right]](https://s0.wp.com/latex.php?latex=L%28x%2Cp%28x%7Cy%29%29%3D%5Cmathbb%7BE%7D_%7Bp%28x%7Cy%29%7D%5Cleft%5B%5Cleft%7Cx-%5Chat%7Bx%7D%28y%29%5Cright%7C%5Ep%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002)
 is a parameter. The limit
is a parameter. The limit  gives the familiar entropy,
gives the familiar entropy, 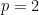 is the conventional squared error, and the best fit to the data was
is the conventional squared error, and the best fit to the data was  , a “square root loss.” It’s hard to provide any normative explanation of why this or any other choice is best (since the loss is basically the definition of ‘best’, and you’d have to relate the theoretical loss to some real consequences in the world), it is very interesting that the efficient coding solution explains data worse than their other Bayesian efficient coding losses.
, a “square root loss.” It’s hard to provide any normative explanation of why this or any other choice is best (since the loss is basically the definition of ‘best’, and you’d have to relate the theoretical loss to some real consequences in the world), it is very interesting that the efficient coding solution explains data worse than their other Bayesian efficient coding losses.