JD Semedo, A Zandvakili, CK Machens, BM Yu, and A Kohn. Neuron, 2019.
Summary
How do populations of neurons in interconnected brain areas communicate? This work proposes the idea that different cortical areas interact through a communication subspace: a low-dimensional subspace of the source population activity fluctuations that is most predictive of the target population fluctuations. Further, this communication subspace is not aligned with the largest activity patterns in a source area. Importantly, the computational advantage of such a subspace is that it allows for selective and flexible routing of signals among cortical areas.
Approach used to study inter-areal interactions
Previous studies of inter-areal interactions in the brain have related spiking activities of pairs of neurons in different brain areas or LFP-LFP interactions. Such studies have provided insight into how interaction strength changes with stimulus drive, attentional states, or task demands. However, these methods do not explain how population spiking activity in different areas are related on a trial-by-trial basis.
This work leverages trial-to-trial co-fluctuations of V1 and V2 neuronal population responses, recorded simultaneously in macaque monkeys, to understand population-level interactions between cortical areas.
Experiment details
The activity of neuronal populations in output layers (2/3-4B) of V1, and the primary downstream target of the middle layers of V2, were recorded in three anesthetized monkeys (Fig 1A in the paper). The recorded populations had retinotopically aligned receptive fields. The stimulus comprised drifting sinusoidal gratings at 8 different orientations. The trial-to-trial fluctuations to repeated presentations of each grating were analyzed.
Source and target populations
The recorded V1 neurons were divided into source and target populations (Fig 1B). For each dataset, the target V1 population was drawn randomly from the full set of V1 neurons such that it matched the neuron count and firing rate distribution of the target V2 population. This matching procedure was repeated 25 times, using different random subsets of neurons. Results for each stimulus condition were based on averages across these repeats.
Results
Strength of population interactions
The V1-V2 interactions were first characterized by (i) measuring noise correlations, and (ii) multivariate linear regression to see how well the variability of the target populations could be explained by the fluctuations of the source V1 population (Fig 2). Both these analyses indicated that the interactions between areas (source V1 – target V2) have similar strength as those within a cortical area (source V1 – target V1).
What about the structure of these interactions?
Consider predicting the activity of a V2 neuron from a population of three V1 neurons using linear regression. The regression weights correspond to a regression dimension. In a basic multivariate regression model, each V2 neuron has its own regression dimension and these dimensions could, in principle, fully span the V1 activity space. But what if they span only a subspace (Fig 3)?
If only a few dimensions of V1 activity are predictive of V2, then using a low dimensional subspace should achieve the same prediction performance as the full regression model.
Testing the existence of these subspaces
To test this hypothesis, the authors used linear regression with a rank constraint. They observed that reduced rank regression achieved nearly the same performance as the full regression model. Further, they observed that the number of dimensions needed to account for V1-V2 interactions was less than the ones involved in V1-V1 interactions (Fig 4).
Are the V1-V2 interactions low dimensional because the V2 population activity itself is lower dimensional that the target V1? Factor analysis revealed that the dimensionality of the V2 activity was actually higher than that of the target V1 (Fig 5A).
To assess how the complexity of the target population influenced the dimensionality of the interactions, they also compared the number of predictive dimensions to the dimensionality of the target population activity (Fig 5B). For V1-V1 interactions, the number of predictive dimensions matched the target V1 dimensionality. In contrast, for V1-V2 interactions, the number of predictive dimensions was consistently lower than the target V2 dimensionality.
Based on these observations, the authors conclude that
- the V1-V1 interaction uses as many predictive dimensions as possible
- but the V1-V2 interaction is confined to a small subspace of source V1 population activity
The authors term this subspace the communication subspace. This low-dimensional interaction structure was also observed in simultaneous population recordings in V1 and V4 of awake monkeys (Fig S2).
Relationship to source population activity
By removing source population activity along required predictive dimensions, they identified that the V2 predictive dimensions are not aligned with target V1 predictive dimensions (Fig 6).
Next, using factor analysis, they identified the dimensions of largest shared fluctuations within the source V1 population. However, these dominant dimensions of the source V1 population are worse than the V2 predictive dimensions at predicting V2 fluctuations (Fig 7A).
Summary of results
The V1 predictive dimensions are aligned with the largest source V1 fluctuations (dominant dimensions, Fig 7B). In contrast, the V2 predictive dimensions are distinct and:
- they are less numerous
- they are not well aligned with the V1 predictive dimensions
- nor are they well aligned with the V1 dominant dimensions
The authors conclude by suggesting that the communication subspace is an advantageous design principle of inter-area communication in the brain. The ability of a source area to communicate only certain patterns while keeping others private could be a means of selective routing of signals between areas. This selective routing allows moment-to-moment modulation of interactions between cortical areas.
Comments from the journal club
- An alternative to reduced rank linear regression would be to use canonical correlation analysis (CCA)
- What information is encoded in the different dimensions, both predictive and dominant? This should be easy to check.
- The analyses here are entirely linear, but V2 neurons most likely perform nonlinear operations on inputs received from V1. The approach used here was to study local fluctuations around set points. The justification provided for this approach is that the trial-to-trial variability around the mean response functions effectively as local linear perturbations in the nonlinear transformation between V1 and V2.
- All the analyses reveal subspaces of relatively low dimensionality. Might this be a consequence of the low-dimensional stimulus? Nonetheless, why would the (“noise”) fluctuations be low-dimensional even for a low-dimensional stimulus?
 ), a basic set of analytical functions (for e.g. sine, cosine), constants and state variables. The search algorithm, based on genetic programming, forms new equations by recombining previous equations and probabilistically varying sub-expressions. These models are associated with a fitness score. Models with high fitness are retained and unpromising solutions are discarded. The algorithm terminates after the obtained equations reach a desired level of fitness.
), a basic set of analytical functions (for e.g. sine, cosine), constants and state variables. The search algorithm, based on genetic programming, forms new equations by recombining previous equations and probabilistically varying sub-expressions. These models are associated with a fitness score. Models with high fitness are retained and unpromising solutions are discarded. The algorithm terminates after the obtained equations reach a desired level of fitness. . . . . . . . . . . . . . . . # conservation law
. . . . . . . . . . . . . . . # conservation law . . . . . . . . . . . . . . . # diff. both sides w.r.t
. . . . . . . . . . . . . . . # diff. both sides w.r.t  , use chain rule
, use chain rule . . . . . . . . . . . . . . . # solve for
. . . . . . . . . . . . . . . # solve for 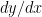 as desired
as desired . . . . . . . . . . . . . . . # note opposite sign!
. . . . . . . . . . . . . . . # note opposite sign!